








2025年04月10日
2025年04月10日配信

近年、ChatGPTをはじめとする生成AI・LLM(大規模言語モデル)が台頭し期待される一方、ハルシネーション(事実と異なる出力)の問題も指摘されています。この課題を軽減しながらLLMを活用する有力な手段として、RAGというフレームワークが注目を集めています。RAGは、適切な情報を参照することで出力の品質を大幅に向上させる手法です。
FRONTEOの発見型AI「KIBIT」は検索に特化したアルゴリズムを持ち、RAGにおいて正しい情報を取得するための「検索」のステップで特に高い効果を発揮します。そのKIBITの検索力をLLMと掛け合わせることで、LLMのみよりもシンプルかつ高精度で企業内の未整理データの活用を実現するAIシステム「匠KIBIT零」もご紹介します。
RAG(Retrieval-Augmented Generation)は、「検索拡張生成」などと訳され、文書生成 AI ・LLM(大規模言語モデル)の情報源として別手段で最適な情報を取得してからLLMに回答文を生成させ、その精度や信頼性を向上させる手法を指します。
これは2020年にMeta社(旧Facebook)の論文にて提示された考え方で、最近のChatGPTを始めとする生成AIの急速な広がりでさらに注目を集めるようになりました。生成AIは自然で説得力のある文章を作れますが、時に誤りや創作が含まれるハルシネーションと呼ばれる現象を起こします。このハルシネーションを、外部情報を参照することで軽減して生成AIを効果的に活用する対策がRAGなのです。
イメージとしては、事前に学習して試験を受けるか、教科書を見ながら試験問題を解いていくかの違いに近いかもしれません。あらかじめ学習してその知識で試験を受けるのがChatGPTなど生成AIの場合(モデルが学習済みの内容から回答を生成)、教科書を見ながら問題を解いていくのがRAG(情報源を参照して回答を生成する)のようなイメージでしょう。
自然言語処理AIの中でも大規模言語モデル(LLM)の発展は急速で、ChatGPTの元のGPT-3.5/4などのみならず、有名なところではGoogleのPaLMやGemini、MetaのLlama 2、最近ではClaudeなど、多くのLLMが次々に開発されています。一方で、LLMに基づく文書生成AIがハルシネーションを起こすことが課題でした。
ハルシネーション(hallucination)とは「幻覚」の意味で、ChatGPTなどの生成AIが時に事実でないことを本当のように語る現象も指すようになりました。この原因は、ChatGPTをはじめLLMに基づく自然言語処理AIが言葉の意味を理解して文章を作るのではなく、次の単語を推測することで文章を紡いでいくことも一因で、この性質のため回答が文脈重視になる傾向があります。その他、古かったり不正確だったりする情報源を参照してしまう場合などもあるためと考えられます。
ハルシネーションへの対策として最も効果的な対応は、AIの出した内容をそのまま鵜呑みにせず、内容を判断できるリテラシーを身につけた上で活用することに尽きます。
ハルシネーションを低減するために取りうる手法としては、プロンプトでの対策や、生成した回答への情報源の付与などが挙げられます。
プロンプトで正確に指示を出す、あるいは段階を分けながら回答させるなどして、AIモデルの回答を制限しつつ、回答をコントロールする方法があります。
参照した情報源のリンクなどを付与しながら回答を生成する手法もあります。利用する人間がファクトチェック(事実確認)をしやすくなり、誤りを正しやすくなります。
LLM(大規模言語モデル)やそれに基づく生成AIの性能を向上させるための手段としては、目的のタスクに関連するデータセットでモデルを再訓練する転移学習やファインチューニングも用いられます。
転移学習とは、ある分野や課題で学習済みのAIモデルはそのままで、新たな出力層の追加によって別の分野や目的に応用させる方法です。獲得済みの知識を活かせるため、別目的でもある程度の性能が期待できます。
ファインチューニングとは、既存の大規模言語モデル(LLM)をベースに、目的のタスクに関連するデータに特化してモデル自体を調整・最適化し、特定領域への適用力を高める方法です。
つまり、転移学習ではAIモデルの元の知識を転用し、ファインチューニングではモデル自体をタスクに特化させます。それに対してRAGは、単にAIモデルをチューニングするのではなく、適切な情報を参照させた上で出力を行うことでその品質を向上できるという違いがあります。
例えば様々な問い合わせへの適切な対応が必要なコールセンターでRAGを活用すれば、AIがマニュアルや対応事例データベースから情報を検索し、回答やその候補を的確に作成できます。オペレーターは調べ作業が不要になり、スムーズに適切な内容を案内できるようになります。
他にも、技術文書作成への活用も考えられます。製品の取扱説明書や技術マニュアルなど、高度な専門知識を伴う文書作成が欠かせない製造業やIT企業などでRAGを活用すれば、AIが関連する技術データなどから必要な情報を検索し、より正確でわかりやすい説明文の作成を補助できます。
RAGのビジネスへの活用が期待されるのは、高度な知識とそれに伴う判断やスキルを補助すべき場面が多くあるためで、様々な業務の知的生産性を飛躍的に高められる可能性があります。
RAG(Retrieval Augmented Generation)は、大きく分けて「検索(Retrieval)」と「生成(Generation)」の2つのステップで構成されています。
まず自然言語(人が通常使う言葉)で問いかけを入力すると、「検索」ステップでは、目的や用途に応じたデータ(社内文書や過去事例の記録など)から、関連する情報を検索します。問いかけ内のキーワードや文脈を手がかりとして、データ中の関連情報を特定し抽出します。
「生成」ステップでは、検索のステップで厳選された関連情報を参照先として、回答となる文章を生成して出力します。
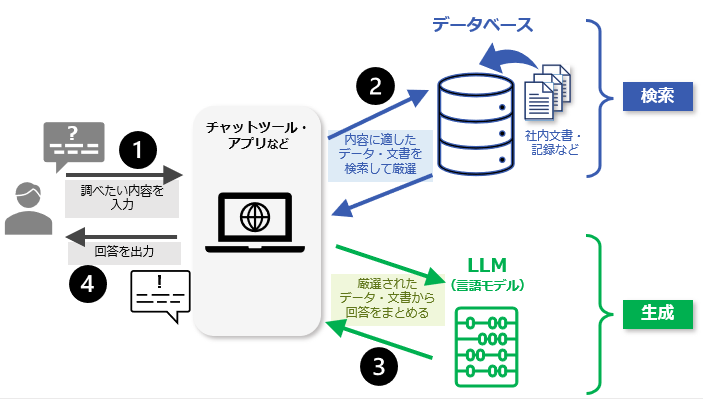
RAGは、生成AIやLLMの出力を補い、強化することを目的としたフレームワークです。RAGの仕組みは、生成AIやLLMの自然言語処理の出力に、企業保有のデータなど確実性の高い関連情報を組み合わせて、出力の適切性や信頼性を高めるというものです。このような、目的のデータと生成AI・LLMを組み合わせたRAGがシナジー効果を生み、様々な分野で知的生産性の向上をもたらすことが期待されています。
RAGの回答精度向上には、「検索」ステップでの工夫が特に重要になります。情報源となるデータの質が出力精度を直接左右するのはもちろん、質問の文脈から関連情報を的確に検索するためのアルゴリズムが、非常に重要になります。
製造業のように多様な人が関わる現場では、業務上の技術や技能の属人化がどこでも課題です。設備故障データや製品不良データ・報告書などが適切に揃い、トラブルが発生してもすぐ解決できることが理想ですが、そうしたデータやドキュメント類は、往々にして未整理な状態のままというケースが多いものです。
「匠KIBIT零」は、検索に強い発見型AI「KIBIT」がRAGの精度をより高め、多くのナレッジが蓄積されてきた企業内の知見やデータを最大限に活用するためのシステムです。
![]()

「発見」に長けたAIエンジンKIBITとLLM・生成AIを掛け合わせた、いわば「いいとこ取り」の匠KIBIT零は、手元にある自社特有のデータから「今」必要な正しい回答や参照先、探したい文書を的確にリストアップできます。これは、KIBITが類似性・関連性を見出す検索力の高い「発見」のための独自アルゴリズムを持つからこそ為せる技です。
匠KIBIT零では、大量のデータから必要な情報を的確に取り出すことができ、取り出した情報の要約が必要な場合は生成AIで要約を出力するというRAGのスキームによってLLMのみよりも高精度な応答を生成できます。LLMを再カスタマイズする従来の手法よりも、はるかにシンプルかつ確実に精度を上げられます。
表記も形式もばらばらな数十年分の未整理データでも、KIBITによる概念検索は業務用語や表記ゆれもクリアできるため、目的の資料や回答の絞り込みも、適切な情報の特定も対応可能です。その結果、正確な回答や参照先に素早くたどり着けるのはもちろん、使用を重ねることで質問力や問題解決力が向上し、一人ひとりが「わかる、応用できる」組織づくりへつながります。そうした自社データの最適な活用が、現場のリードタイムの短縮、そして知見を常に共有できる組織変革にもつながっていきます。



{kind=link}
{kind=link}
{kind=link}